背景
8月25日的会议讨论了证据效力模型。几个基本概念:
诉求、证据、证据采信、诉求支持。
- 一个案件包括一个或多个诉求,譬如一个案件有离婚和分财产两种诉求。
- 一个诉求对应一个或多个证据
- 特定案由的诉求集合是有限并确定的。譬如离婚按由一般对应{“请求离婚”,“请求分财产”,…}这几个诉求
- 特定诉求的证据集合是有限并确定的。譬如离婚诉求对应了证据集{家暴,感情不和,…}
- 每个证据有采信和不采信两种结果,可以从文书中解析获得
- 每个被采信的证据对诉求影响程度不同,称为效力
- 诉求是否被支持是由证据决定(证据是否被采信、被采信的证据的效力)的
在算法方面,我们希望模型能够计算出:
- 证据的采信度。即反映证据被采信的概率。
- 证据的效力大小。即反映单个证据对于法院支持诉求的影响程度。
- 证据的综合充分度/所有证据的综合效力。即对于所有证据,我们假设证据被已经被采信、证据的效力大小得出的综合分数。
? 证据的充分度这个指标,是否要把证据是否会被采信(及采信度)考虑进来,和张文秀讨论决定不考虑,就是说,假设证据一定会被采信,因此模型训练时就要筛选出所有被采信的证据。
数据
原始数据
通过判决文书获得。判决文书记录了
- 诉求
- 诉求相关的证据
- 证据是否被采信
- 诉求是否被支持。
算法组需要的数据
证据-诉求列表,其中证据列是0、1二值,表示是否存在该证据;其中诉求列是-1,0,1三值,-1表示该案件不存在该诉求,0表示该诉求存在且不被法院支持,1表示该诉求存在且被法院支持。
对于离婚纠纷案由,示例证据-诉求列表如下:
| 文书id | 证据1 | 证据2 | … | 证据N1 | 诉求1是否被法院支持 | … | 诉求N2是否被法院支持 |
|---|---|---|---|---|---|---|---|
| 1 | 0 | 1 | … | 1 | -1 | … | -1 |
| 2 | 1 | 0 | … | 1 | 0 | … | -1 |
| … | |||||||
| N | … |
证据-诉求关系:指出一个诉求一般由哪些证据支持以及哪些其他诉求支持。
例如对于离婚纠纷案由,一般有2个诉求:请求离婚、请求分割财产。我们需要获得请求离婚这个诉求相关的证据,和请求分割财产相关的证据。
{
"案由": "离婚",
"诉求": {
"请求离婚": {
"证据": ["家庭暴力", "有赌博、吸毒等恶习屡教不改", "因感情不和分居满二年的"],
"基于的其他诉求": ["房产证", "首付出资证明"]
},
"分割财产": {
"证据": [""],
"基于的其他诉求": ["请求离婚"]
}
}
}证据采信度
证据的采信度。即反映证据被采信的概率。
这个比较简单,对于证据 E ,直接简单统计一下出现过证据 E 的文书总数 S,以及证据 E 被采信的文书数量 S1,采信率
R(E) = S1 / S证据的效力大小
证据的效力大小分为:
- 单个证据的效力大小
- 所有证据的综合效力大小
经过讨论,证据效力大小值是在默认证据会被采信的情况下得出的,因此模型训练数据应该是筛选出所有被采信的证据,忽略未被采信的数据。
那么如何定义效力大小及计算方式?
基本出发点是,我们认为,所有证据的综合效力越大,诉求被支持的概率越大。因此不妨将综合效力大小用诉求被支持的概率来描述,即在“证据-诉求是否被支持”的二分类问题中,计算被支持的概率。
而所有证据综合效力大小可以认为是由单个证据效力大小的加和。因此只要计算出每个特征对类概率的贡献度,就可以作为单个证据效力的大小。
因此问题转换为如何计算二分类概率以及每个特征对类概率的影响,我们可以使用 Lime 项目来解决该问题。
Lime —— 对任意算法单个样本预测进行解释
Lime 是一个2016年2月提出的算法
旨在解决模型的可解释性问题,声称可以解释任意机器学习模型。它能够解释任意模型的原因是,它不是对整体模型进行解释,而是对于单次预测样本进行解释,对于单次预测样本,他对原有模型的样本在临近处学习出一个本地线性逼近的对数几率回归模型,因此可以给出分类概率以及每个特征的对应的概率。
Intuitively, an explanation is a local linear approximation of the model's behaviour. While the model may be very complex globally, it is easier to approximate it around the vicinity of a particular instance. While treating the model as a black box, we perturb the instance we want to explain and learn a sparse linear model around it, as an explanation. The figure below illustrates the intuition for this procedure. The model's decision function is represented by the blue/pink background, and is clearly nonlinear. The bright red cross is the instance being explained (let's call it X). We sample instances around X, and weight them according to their proximity to X (weight here is indicated by size). We then learn a linear model (dashed line) that approximates the model well in the vicinity of X, but not necessarily globally. For more information, read our paper, or take a look at this blog post.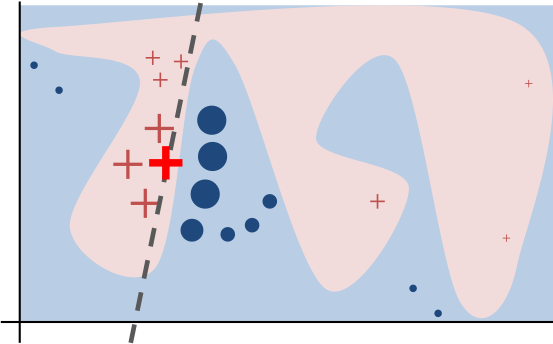
譬如对于一个文本分类任务,Lime给出的预测如下:

左边是每个分类的概率。可以看出 atheism(无神论者) 概率最高,为0.5,右边可以看出究竟是哪些特征(词)产生了该概率, 可以看出 Caused,Rice,Genocide 这些词(特征)决定了对 atheism 的预测。并且我们可以给出它们的概率贡献值。
所以,对于我们的证据效力模型,我们也可以使用该方法算出证据总效力,以及每个证据的效力。
其他模型
除了lime以外,treeinterpreter 也是一个使用局部线性逼近来解释预测过程的项目,他会对输入的样本和模型,给出
prediction = bias + feature_1_contribution + ... + feature_n_contribution可用性
Lime 和 Lime 都可以在 sklearn 上运行,并且使用的 BSD 协议,符合项目约束。具体效果有待测试。
总结及下一步工作
证据效力模型的需求、数据要求、算法初步实现方案都在文中进行了描述。如果需求描述有问题请大家及时指出,接下来,还要孙艺博沟通一下数据数据问题,算法方面需要测试对比提出的算法实际效果如何。